Spring Cloud是一系列框架的有序集合。它利用Spring Boot的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册、配置中心、消息总线、负载均衡、断路器、数据监控等,都可以用Spring Boot的开发风格做到一键启动和部署。Spring Cloud并没有重复制造轮子,它只是将各家公司开发的比较成熟、经得起实际考验的服务框架组合起来,通过Spring Boot风格进行再封装屏蔽掉了复杂的配置和实现原理,最终给开发者留出了一套简单易懂、易部署和易维护的分布式系统开发工具包。
什么是微服务
提出者与时间: Martin Fowler ,Mar 2014
微服务架构是一种架构模式,它提倡单一应用程序划分成一组小的服务,服务之间互相协调,互相配合,为用户提供最终价值.每个微服务运行在其独立的进程中,服务与服务间采用轻量级的通信机制互相协作(通常是基于http协议的restful api).每个服务都围绕着具体业务进行构建,并且能够内独立的部署到生产环境,类生产环境等。
微服务技术栈
| 微服务条目 | 微服务落地技术 |
|---|---|
| 服务注册中心 | Eureka、Zookeeper、Consul、Nacos |
| 服务调用 | Ribbon、LoadBalance、Feign、OpenFeign |
| 服务降级 | Hystrix、Sentinel、resilience4j |
| 服务网关 | Zuul、gateway |
| 服务配置 | Config、Nacos |
| 服务总线 | Bus、Nacos |
SpringCloud是分布式微服务架构一站式解决方案,是多种微服务架构落地技术的集合体,俗称微服务全家桶。
Eureka
Eureka是什么?
Eureka 是 Netflix 开发的,一个基于 REST 服务的,服务注册与发现的组件,以实现中间层服务器的负载平衡和故障转移。
它主要包括两个组件:Eureka Server 和 Eureka Client
Eureka Client:一个Java客户端,用于简化与 Eureka Server 的交互(通常就是微服务中的客户端和服务端)
Eureka Server:提供服务注册和发现的能力(通常就是微服务中的注册中心)。
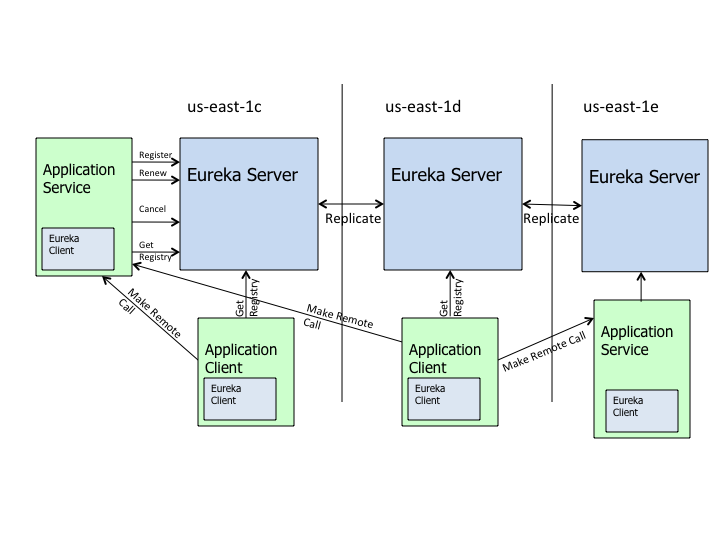
服务启动后向Eureka注册,Eureka Server会将注册的信息向其他Eureka Server进行同步,当服务消费者要调用服务提供者,则向服务注册中心获取提供者地址,然会会将服务提供者地址缓存到本地,下次调用时,直接在本地缓存中取,完成一次调用。
当注册中线Eureka Server检测到服务提供者因为宕机、网络原因不可用时,则会在服务中心将服务置为DOWN状态,并把当前服务提供者状态向订阅者发布,订阅过的服务消费者更新本地缓存。
服务提供者在启动后,周期性(默认30秒)向Eureka Server发送心跳,以证明当前服务是可用状态。Eureka Server在一定的时间(默认90秒)未收到客户端的心跳,则认为服务宕机,注销该实例。
Eureka心跳机制
在应用启动后,节点们将会向Eureka Server发送心跳,默认周期为30秒,如果Eureka Server在多个心跳周期内没有接收到某个节点的心跳,Eureka Server将会从服务注册表中把这个服务节点移除(默认90秒)。
Eureka自我保护模式
自我保护机制的工作机制是:如果在15分钟内超过85%的客户端节点都没有正常的心跳,那么Eureka就认为客户端与注册中心出现了网络故障,Eureka Server自动进入自我保护机制,此时会出现以下几种情况:
- Eureka Server不再从注册列表中移除因为长时间没收到心跳而应该过期的服务。
- Eureka Server仍然能够接受新服务的注册和查询请求,但是不会被同步到其它节点上,保证当前节点依然可用。
- 当网络稳定时,当前Eureka Server新的注册信息会被同步到其它节点中。
Eureka自我保护机制,通过配置 eureka.server.enable-self-preservation 来true打开false禁用自我保护机制,默认打开状态,建议生产环境打开此配置。
Eureka Server高可用集群
相互注册,相互守望
- 修改host文件
windows目录:C:\Windows\System32\drivers\etc\hosts
linux目录:/etc/hosts
1 | Eureka |
- 建立两个子模块
- 修改pom文件
- 启动类添加注解
@EnableEurekaServer - 修改yml文件
1 | server: |
在配置文件中相互注册即可。
注:如果要在服务消费者使用RestTemplate调用服务提供者,需要使用@LoadBalanced注解,来为RestTemplate赋予负载均衡的能力。
服务高可用
1 | eureka: |
将服务注册到多个Eureka上,多个地址用,隔开就可。
消费者使用RestTemplate进行调用
1 | ("/payment/{id}") |
Zookeeper
ZooKeeper 是一个分布式的,开放源码的分布式应用程序协调服务,它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等。 Zookeeper是hadoop的一个子项目,其发展历程无需赘述。在分布式应用中,由于工程师不能很好地使用锁机制,以及基于消息的协调机制不适合在 某些应用中使用,因此需要有一种可靠的、可扩展的、分布式的、可配置的协调机制来统一系统的状态。基于java开发。
centos上安装zookeeper

官网复制下载地址https://downloads.apache.org/zookeeper/
下载wget https://downloads.apache.org/zookeeper/zookeeper-3.5.9/apache-zookeeper-3.5.9-bin.tar.gz
解压tar -zxvf apache-zookeeper-3.6.3-bin
进入目录cd apache-zookeeper-3.6.3-bin
创建data目录mkdir data
进入conf目录cd conf
重命名/拷贝zoo_sample.cfg,修改为zoo.cfgmv zoo_sample.cfg zoo.cfg
vim进入zookeepervim zoo.cfg
修改zoo.cfg文件,修改datadir为刚才创建的目录
进入bin目录,启动zookeeper
./zkServer.sh start查看状态
./zkServer.sh status启动客户端
./zkCli.sh
应用接入
引入依赖
1 | <dependency> |
这里要注意版本冲突的问题,如果不能正常启动,需要剔除zookeeper的依赖,添加对应版本的依赖
配置
1 | spring: |
zookeeper客户端启动./zkCli.sh
查看节点信息
1 | [zk: localhost:2181(CONNECTED) 0] ls / |
注意:Zookeeper中的节点是临时的,如果下次没有收到心跳的话就会被移除掉,再次上线的节点的id也会不一样。
CAP理论
C:Consistency,数据一致性
A:Availability,可用性,系统响应速度
P:Partition tolerance,分区容错性
著名的CAP理论指出,一个分布式系统不可能同时满足C(一致性)、A(可用性)和P(分区容错性)。由于分区容错性在是分布式系统中必须要保证的,因此我们只能在A和C之间进行权衡。在此Zookeeper保证的是CP, 而Eureka则是AP。
Zookeeper保证CP。当向注册中心查询服务列表时,我们可以容忍注册中心返回的是几分钟以前的注册信息,但不能接受服务直接down掉不可用。也就是说,服务注册功能对可用性的要求要高于一致性。但是zk会出现这样一种情况,当master节点因为网络故障与其他节点失去联系时,剩余节点会重新进行leader选举。问题在于,选举leader的时间太长,30 ~ 120s, 且选举期间整个zk集群都是不可用的,这就导致在选举期间注册服务瘫痪。在云部署的环境下,因网络问题使得zk集群失去master节点是较大概率会发生的事,虽然服务能够最终恢复,但是漫长的选举时间导致的注册长期不可用是不能容忍的。
Eureka保证AP。Eureka看明白了这一点,因此在设计时就优先保证可用性。Eureka各个节点都是平等的,几个节点挂掉不会影响正常节点的工作,剩余的节点依然可以提供注册和查询服务。而Eureka的客户端在向某个Eureka注册或时如果发现连接失败,则会自动切换至其它节点,只要有一台Eureka还在,就能保证注册服务可用(保证可用性),只不过查到的信息可能不是最新的(不保证强一致性)。除此之外,Eureka还有一种自我保护机制,如果在15分钟内超过85%的节点都没有正常的心跳,那么Eureka就认为客户端与注册中心出现了网络故障,此时会出现以下几种情况:
- Eureka不再从注册列表中移除因为长时间没收到心跳而应该过期的服务
- Eureka仍然能够接受新服务的注册和查询请求,但是不会被同步到其它节点上(即保证当前节点依然可用)
- 当网络稳定时,当前实例新的注册信息会被同步到其它节点中
因此, Eureka可以很好的应对因网络故障导致部分节点失去联系的情况,而不会像zookeeper那样使整个注册服务瘫痪。
Consul
Consul是一套开源的分布式服务发现和配置管理系统,由HashiCorp公司用Go语言开发。
提供了微服务系统中的服务治理、配置中心、控制总线等功能。这些功能的每一个都可以根据需要单独使用,也可以一起使用构建全方位的服务网格,总之Consul提供了一套完整的服务网格解决方案。
consul安装与启动
直接官网下载即可,解压完是一个exe可执行文件
在解压的文件夹下打开cmd,输入consul即可完成安装
输入consul -v查看consul版本信息。
输入consul agent -dev启动consul,访问localhost:8500。
应用接入
引入依赖
1 | <dependency> |
配置文件
1 | server: |
三个注册中心的异同
| 组件名 | 语言 | CAP | 服务检查检查 | 对外暴露接口 | SpringCloud集成 |
|---|---|---|---|---|---|
| Eureka | Java | AP | 可配支持 | HTTP | 已集成 |
| Consul | Go | CP | 支持 | HTTP/DNS | 已集成 |
| Zookeeper | Java | CP | 支持 | 客户端 | 已集成 |
Ribbon
SpringCloud Ribbon是基于Netflix Ribbon实现的一套客户端。(负载均衡工具)
简单的说,Ribbon是Netflix发布的开源项目,主要功能是提供客户端的软件负载均衡算法和服务调用。Ribbon客户端主键提供一系列完善的配置项:如连接超时,重试等。简单的说,就是在配置文件中列出Load Blance后面的所有机器,Ribbon会自动帮助你基于某种规则去连接这些机器。我们很容易使用Ribbon实现自定义的负载均衡算法。
虽然现在Ribbon已经停止维护,但是还是有不少人使用。
主要的模块有Ribbon-HTTPClient,Ribbon-eureka,Ribbon-Loadbalance
Ribbon本地负载均衡 VS Nginx服务端负载均衡
Nginx是服务器负载均衡,客户端所以请求都会交给Nginx,然后由Nginx实现转发请求。即负载均衡是服务端实现的。
Ribbon负载均衡是客户端本地的负载均衡,分为集中式和进程式。
集中式:
在服务的消费方和提供方之间使用独立的负载均衡设施(可以是硬件也可以是软件),由该设施负责请求访问,通过某种策略转发到服务的提供方。
进程式:
将负载均衡的逻辑集成到消费方,消费方从服务注册中心获取哪些服务可用,然后自己再从这些服务中选择出一个合适的服务器。Ribbon属于进程内负载均衡。他是一个类库,继承消费方进程,消费方通过获取到服务提供方的地址。
Ribbon工作原理:
- 先选择Eureka Server,他会选择在同一个区域内负载均衡较少的Server。
- 根据用户指定的策略,从Server取到的服务注册列表中选择一个地址
其中Ribbon提供了多种策略:如果轮询、随机,根据响应时间加权等。
基本使用
1 | <dependency> |
默认情况下,Eureka-Client依赖中含有Ribbon的依赖,不需要再次引入。
Ribbon的核心组件IRule
IRule是以下七种负载均衡算法的父接口
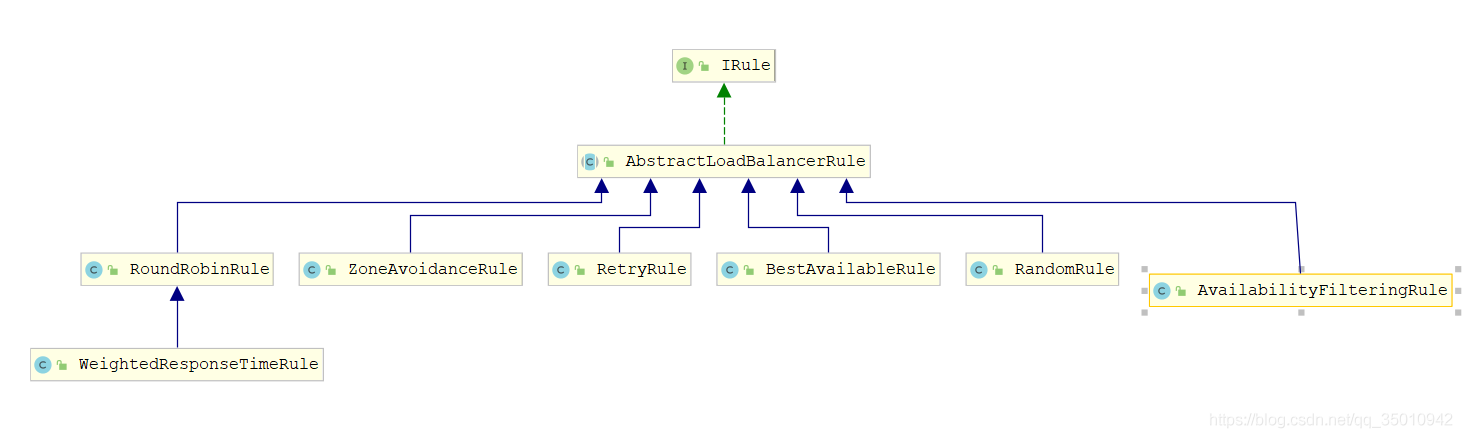

- RoundRobinRule: 默认轮询的方式
- RandomRule: 随机方式
- WeightedResponseTimeRule: 根据响应时间来分配权重的方式,响应的越快,分配的值越大。
- BestAvailableRule: 选择并发量最小的方式
- RetryRule: 在一个配置时间段内当选择server不成功,则一直尝试使用subRule的方式选择一个可用的server
- ZoneAvoidanceRule: 根据性能和可用性来选择。
- AvailabilityFilteringRule: 过滤掉那些因为一直连接失败的被标记为circuit tripped的后端server,并过滤掉那些高并发的的后端server(active connections 超过配置的阈值)
修改负载均衡算法
首先增加配置类,需要注意的是,自定义的配置类不能被@ComponentScan注解扫描到,所以自定义的IRule不要放在启动类的子目录,要与启动类隔离开。
目录结构
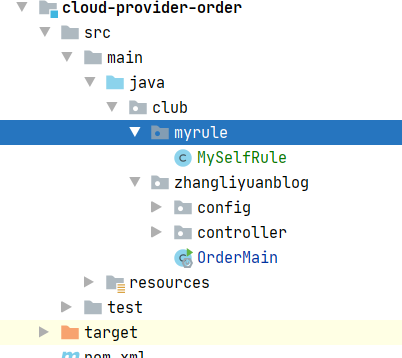
MySelfRule类
1 |
|
在启动类上添加注解@RibbonClient(name = "CLOUD-PAYMENT-SERVICE", configuration = MySelfRule.class)
Ribbon负载均衡算法原理
轮询方法:rest接口第几次请求数对服务集群总数量取余操作,得到结果就是实际调用服务器的下标,每次服务器重启后rest接口计数从1开始。
例如有两台服务提供者,instances[0] = 127.0.0.1:8001,instances[1] = 127.0.0.1:8002,两台实例作为两台机器,集群总数是2,按照轮询算法原理。
当第1请求时, 1%2 = 1,所以获取服务地址是127.0.0.1:8001;
当第2请求时, 2%2 = 0,所以获取服务地址是127.0.0.1:8002;
当第3请求时, 3%2 = 1,所以获取服务地址是127.0.0.1:8001;
当第4请求时, 4%2 = 0,所以获取服务地址是127.0.0.1:8002;
以此类推…
手写负载轮询算法
首先写一个接口
1 | /** |
接口的实现
1 |
|
这里使用CAS自旋的操作。
消费者对应的方法
1 | ("/lb") |
OpenFeign
简介
OpenFeign为微服务架构下服务之间的调用提供了解决方案,OpenFeign是一种声明式、模板化的HTTP客户端。在SpringCloud中使用OpenFeign,可以做到使用HTTP请求访问远程服务,就像调用本地方法一样,开发者完全感知不到这是在调用远程方法,更感知不到在访问HTTP请求。
Feign内置了Ribbon,用来做客户端负载均衡,去调用服务注册中心的服务。Feign本身不支持Spring MVC的注解,它有一套自己的注解。OpenFeign是Spring Cloud 在Feign的基础上支持了Spring MVC的注解,如
@RequesMapping等等。
使用OpenFeign实现服务调用
引入依赖
1 | <dependency> |
编写配置文件,正常注册到eureka上就行。
1 | server: |
编写启动类,并在启动类上开启OpenFeign的注解EnableFeignClients
编写业务类PaymentFeignService,使用FeignClient注解,value为要调用的微服务名称。
1 | /** |
这里碰到一个坑,写路径和参事时一定要写全,不然创建bean的时候会失败。
controller正调用即可。
配置服务超时
OpenFeign的默认超时时间为1s
服务提供者的测试方法
1 | (value = "/timeout/{timeout}") |
修改默认超时时间
1 | ribbon: |
日志打印功能
Feign提供了日志打印功能,我们可以通过配置来调整日志级别,从而了解Feign中HTTP请求的细节。
说白了就是对Feign接口的调用情况监控和输出。
支持四个级别
- NONE: 默认的,不显示任何日志
- BASIC: 仅记录请求方法、URL、响应状态码以及执行时间
- HEADERS:除了BASIC 中自定义的信息外,还有请求和响应的信息头
- FULL: 除了HEADERS中定义的信息外, 还有请求和响应的正文以及元数据。
创建日志配置类
1 | /** |
配置文件修改对应的文件日志打印级别为debug
1 | logging: |
修改成功
Hystrix
服务雪崩
分布式系统环境下,服务间类似依赖非常常见,一个业务调用通常依赖多个基础服务。如下图,对于同步调用,当库存服务不可用时,商品服务请求线程被阻塞,当有大批量请求调用库存服务时,最终可能导致整个商品服务资源耗尽,无法继续对外提供服务。并且这种不可用可能沿请求调用链向上传递,这种现象被称为雪崩效应。
雪崩效应常见场景
- 硬件故障:如服务器宕机,机房断电,光纤被挖断等。
- 流量激增:如异常流量,重试加大流量等。
- 缓存穿透:一般发生在应用重启,所有缓存失效时,以及短时间内大量缓存失效时。大量的缓存不命中,使请求直击后端服务,造成服务提供者超负荷运行,引起服务不可用。
- 程序BUG:如程序逻辑导致内存泄漏,JVM长时间FullGC等。
- 同步等待:服务间采用同步调用模式,同步等待造成的资源耗尽。
雪崩效应应对策略
- 硬件故障:多机房容灾、异地多活等。
- 流量激增:服务自动扩容,流量控制等。
- 缓存穿透:缓存预加载、缓存异步加载等。
- 程序BUG:修改程序BUG、及时释放资源等。
- 同步等待:资源隔离、MQ解耦、不可用服务调用快速失败等。资源隔离通常指不同服务调用采用不同的线程池;不可用服务调用快速失败一般通过熔断器模式结合超时机制实现。
综上所述,如果一个应用不能对来自依赖的故障进行隔离,那该应用本身就处在被拖垮的风险中。 因此,为了构建稳定、可靠的分布式系统,我们的服务应当具有自我保护能力,当依赖服务不可用时,当前服务启动自我保护功能,从而避免发生雪崩效应。
Hystrix概念
Hystrix [hɪst’rɪks],中文含义是豪猪,因其背上长满棘刺,从而拥有了自我保护的能力。本文所说的Hystrix是Netflix开源的一款容错框架,同样具有自我保护能力。为了实现容错和自我保护,下面我们看看Hystrix如何设计和实现的。
Hystrix设计目标:
- 对来自依赖的延迟和故障进行控制和防护–这些依赖通常都是通过网络访问的。
- 阻止故障的连锁反应
- 快速失败并迅速恢复
- 回退并优雅降级
- 提供近实时的监控与告警
Hystrxi遵循的设计原则
- 防止任何单独的依赖耗尽资源(线程)
- 过载立即切断并快速失败,防止排队
- 尽可能提供回退以保证用户免受故障
- 使用隔离技术(例如隔板,泳道和断路器模式)来限制任何一个依赖的影响
- 通过近实时的指标,监控和警告,确保故障被及时发现
- 通过动态修改配置属性,确保故障及时恢复
- 防止整个依赖客户端执行失败,而不仅仅是网络通信
Hystrix如何实现这些目标
- 使用命令模式将所有对外服务的调用包装在HystrixCommand后者HystrixObservableCommand对象中,并将该对象单独放在线程中执行。
- 每个依赖都维护着一个线程池(或者信号量),线程池被耗尽则拒绝请求,而不是让请求排队。
- 记录请求成功,失败和超时和线程拒绝。
- 服务错误百分比超过阈值,熔断器自动打开,一段时间内停止对该服务的所有请求。
- 请求失败,被拒绝,超时或者熔断时执行降级逻辑。
服务提供者配置服务降级
引入依赖
1 | <dependency> |
启动类开启熔断@EnableCircuitBreaker
业务类
1 | (fallbackMethod = "paymentTimeoutHandle", commandProperties = { |
fallbackMethod为发生错误时,调用的方法,这里要注意一下,备用方法的参数要和正常方法的参数对应,不然会报错。
服务消费者配置服务降级
在配置文件中开启Feign对Hystrix的支持
1 | feign: |
启动类开启Hystrix@EnableHystrix
同样在业务类进行配置
1 | (value = "/timeout/{time}") |
这里遇到了一个坑,开始只要后端超过1s就会超时,后来配置了ribbon的超时时间也没有生效。
这里关键在于我们开启了feign.hystrix.enable=true,官网解释说这个配置Feign将适应断路器包装所有的方法(类似于在这些方法上加了一个@HystrixCommand),这些方法会应用一个默认的超时时间1s,所有service超过1s就会报异常,进入备用方法
我们需要修改Hystrix和Ribbon的超时时间
1 | # 配置Ribbon超时 |
配置了这么多超时时间,我具体也不清楚默认采用哪个,看网上大神说应该是timeoutInMilliseconds 和ribbon的ReadTimeout 以及注解中配置的时间取最低值。
目前问题
每个方法都要配置一个 代码膨胀
和业务逻辑混在一起 混乱
通配服务降级DefaultProperties
在对应类使用@DefaultProperties(defaultFallback = "orderTimeoutHandleGlobal")注解,defaultFallback指定方法,这里的方法参数不用和正常方法一致。
如果某个方法需要特殊的 备用方法,也可以使用@HystrixCommand进行指定。
同样服务降级FeignFallBack
我们发现备用的方法和正常的方法写在一起,导致代码很混乱,所以我们可以单独的定义一个类负责一个微服务的备用方法。
首先写一个PaymentFallBackService类继承PaymentHystrixService接口,首先对应微服务的所有方法。
然后我们在PaymentHystrixService的@FeignClient注解的fallback属性指定对应的类即可。
模拟服务的提供者宕机。
服务熔断
1 | // =============服务熔断 |
Hystrix断路器使用时最常用的三个重要指标参数
在微服务中使用Hystrix 作为断路器时,通常涉及到以下三个重要的指标参数(这里是写在@HystrixProperties注解中,当然实际项目中可以全局配置在yml或properties中)
1、circuitBreaker.sleepWindowInMilliseconds
断路器的快照时间窗,也叫做窗口期。可以理解为一个触发断路器的周期时间值,默认为10秒(10000)。
2、circuitBreaker.requestVolumeThreshold
断路器的窗口期内触发断路的请求阈值,默认为20。换句话说,假如某个窗口期内的请求总数都不到该配置值,那么断路器连发生的资格都没有。断路器在该窗口期内将不会被打开。
3、circuitBreaker.errorThresholdPercentage
断路器的窗口期内能够容忍的错误百分比阈值,默认为50(也就是说默认容忍50%的错误率)。打个比方,假如一个窗口期内,发生了100次服务请求,其中50次出现了错误。在这样的情况下,断路器将会被打开。在该窗口期结束之前,即使第51次请求没有发生异常,也将被执行fallback逻辑。
综上所述,在以上三个参数缺省的情况下,Hystrix断路器触发的默认策略为:
在10秒内,发生20次以上的请求时,假如错误率达到50%以上,则断路器将被打开。(当一个窗口期过去的时候,断路器将变成半开(HALF-OPEN)状态,如果这时候发生的请求正常,则关闭,否则又打开)
Hystrix工作流程
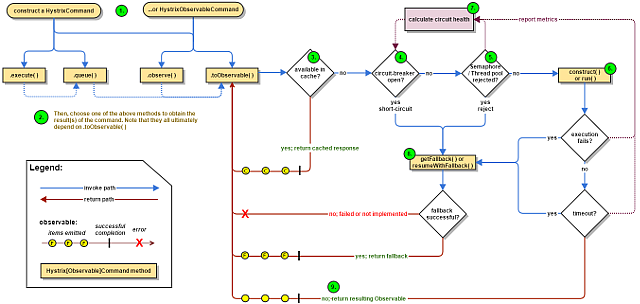
- 构造一个HystrixCommand或者HystrixObservableCommand对象,用于封装请求,并在构造方法配置请求被执行需要的参数。
- 执行命令,Hystrix提供了四种执行命令的方法。
- 判断是否使用缓存响应请求,若启用了缓存,且缓存可用,直接使用缓存响应请求。Hystrix支持请求缓存,但需要用户开启。
- 判断熔断器是否打开,如果打开,跳到第8步。
- 判断线程池/队列/信号量是否已满,已满跳到第8步。
- 执行HystrixObservableCommand.construct()或者HystrixCommand.run(),如果执行失败或者超时跳到第8步,否则跳到第9步。
- 统计熔断器监控指标
- 走Fallback备用逻辑。
- 返回请求响应。
Hystrix图形化监控
新建模块,引入依赖
1 | <dependency> |
启动类开启监控@EnableHystrixDashboard
需要监控的项目在启动类添加如下代码:
1 |
|
访问localhost:9001/hystrix


GateWay
Spring Cloud Gateway 是Spring官方基于Spring5.0,Spring Boot2.0和Project Reactor等技术开发的网关,Spring Cloud Gateway旨在为微服务架构提供一种简单而有效的统一的API路由管理方式。Spring Cloud Gateway作为Spring Cloud生态系中的网关,目标是替代ZUUL,其不仅提供统一的路由方式,并且基于Filter链的方式提供了网关基本的功能,例如:安全,监控/埋点,和限流等。
为什么使用GateWay?
Spring Cloud Gateway 可以看做是一个 Zuul 1.x 的升级版和代替品,比 Zuul 2 更早的使用 Netty 实现异步 IO,从而实现了一个简单、比 Zuul 1.x 更高效的、与 Spring Cloud 紧密配合的 API 网关。
Spring Cloud Gateway 里明确的区分了 Router 和 Filter,并且一个很大的特点是内置了非常多的开箱即用功能,并且都可以通过 SpringBoot 配置或者手工编码链式调用来使用。
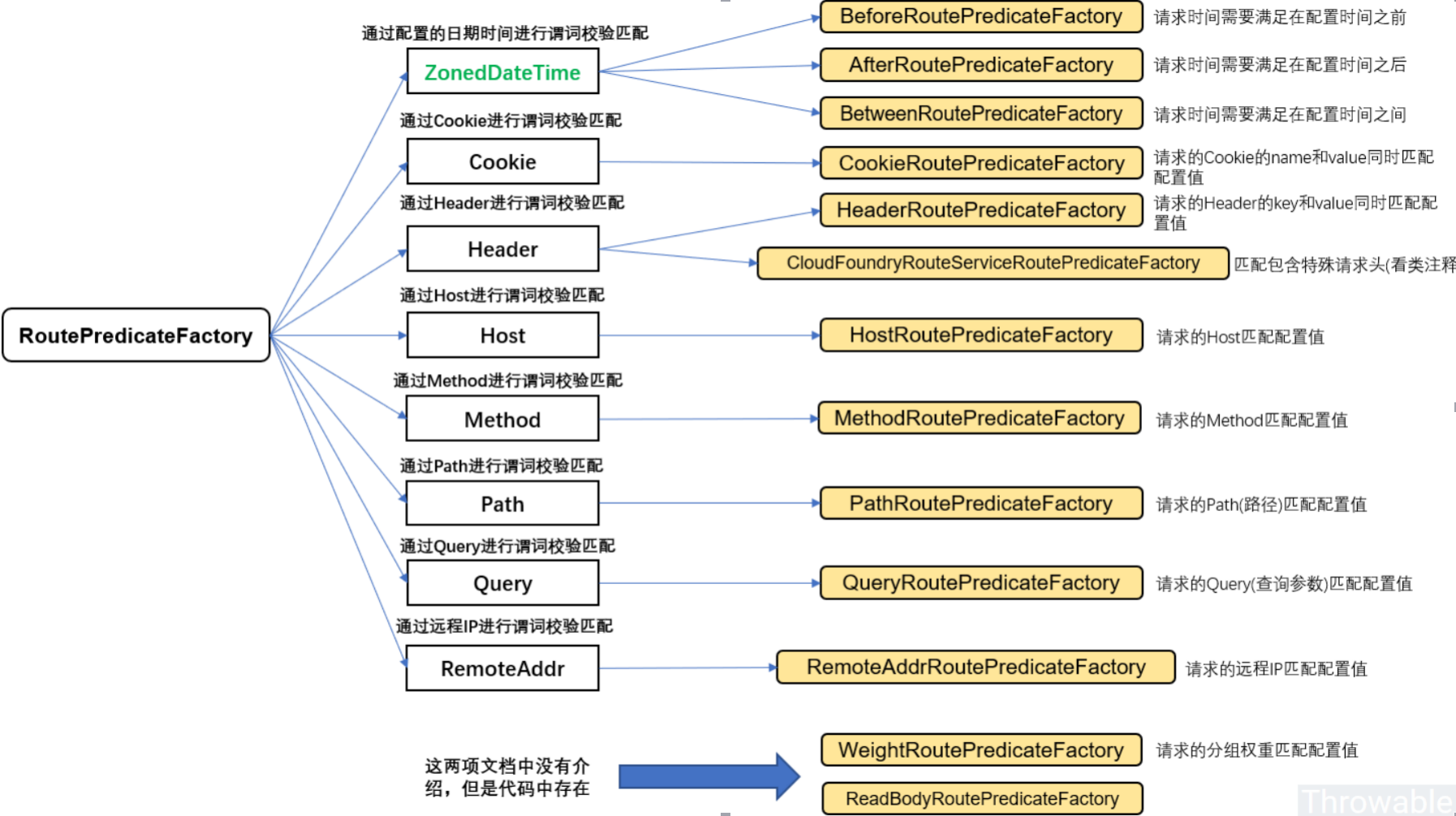
比如内置了 10 种 Router,使得我们可以直接配置一下就可以随心所欲的根据 Header、或者 Path、或者 Host、或者 Query 来做路由。
比如区分了一般的 Filter 和全局 Filter,内置了 20 种 Filter 和 9 种全局 Filter,也都可以直接用。当然自定义 Filter 也非常方便。
重要的几个概念

入门配置
引入依赖
1 | <dependency> |
注意这里不要添加Spring的web依赖和图形化界面依赖
yml文件
1 | eureka: |
这里需要注意在配置多个路由的同时格式要对应。
测试访问http://localhost:9527/payment/1
硬编码配置
1 |
|
配置动态路由
默认情况下GateWay会根据注册中心的服务列表,以注册中心上的微服务名为路径创建动态路由进行转发,从而实现动态路由功能。
1 | spring: |
开启从注册中心动态的创建路由
下面的uri要写成lb://服务名的形式,uri: lb://cloud-payment-service # 匹配后提供服务者的路由
这里的lb表示协议的意思,意为启用GateWay的负载均衡功能
Predicate的使用
通过请求路径进行匹配
1 | spring: |
如果单个参数支持{参数名}的形式。
通过时间匹配
Predicate 支持设置一个时间,在请求进行转发的时候,可以通过判断在这个时间之前或者之后进行转发。
1 | spring: |
Spring 是通过 ZonedDateTime 来对时间进行的对比,ZonedDateTime 是 Java 8 中日期时间功能里,用于表示带时区的日期与时间信息的类,ZonedDateTime 支持通过时区来设置时间,中国的时区是:Asia/Shanghai。
同时GateWay支持使用Before和Between
通过Cookie匹配
Cookie Route Predicate 可以接收两个参数,一个是 Cookie name , 一个是正则表达式,路由规则会通过获取对应的 Cookie name 值和正则表达式去匹配,如果匹配上就会执行路由,如果没有匹配上则不执行。
1 | spring: |
使用curl测试
1 | curl http://localhost:9527/payment/lb --cookie "username=zzyy" |
通过请求方法匹配
可以通过是 POST、GET、PUT、DELETE 等不同的请求方式来进行路由。
1 | spring: |
测试
1 | curl http://localhost:9527/payment/lb |
通过请求参数匹配
1 | spring: |
测试
1 | curl http://localhost:9527/payment/lb?testParameter=11 |
通过请求 ip 地址进行匹配
Predicate 也支持通过设置某个 ip 区间号段的请求才会路由,RemoteAddr Route Predicate 接受 cidr 符号 (IPv4 或 IPv6) 字符串的列表(最小大小为 1),例如 192.168.0.1/16 (其中 192.168.0.1 是 IP 地址,16 是子网掩码)。
1 | spring: |
各种 Predicates 同时存在于同一个路由时,请求必须同时满足所有的条件才被这个路由匹配。
一个请求满足多个路由的断言条件时,请求只会被首个成功匹配的路由转发
Filter
自定义Filter
我们需要实现GlobalFilter, Ordered两个接口。
需要携带uname参数的情况。
1 | 4j |
Config
在分布式系统中,由于服务数量巨多,为了方便服务配置文件统一管理,实时更新,所以需要分布式配置中心组件。Spring Cloud Config项目是就是这样一个解决分布式系统的配置管理方案。它包含了Client和Server两个部分,server提供配置文件的存储、以接口的形式将配置文件的内容提供出去,client通过接口获取数据、并依据此数据初始化自己的应用。
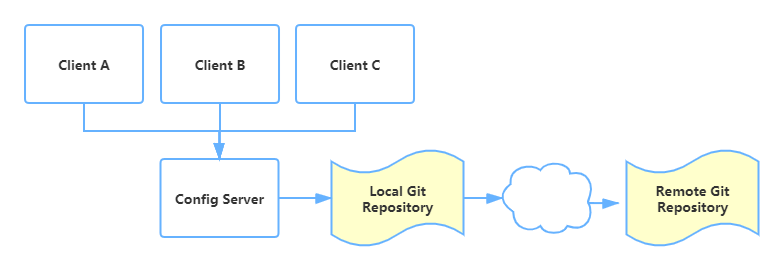
入门示例:
在GitHub上新建一个仓库,放三个配置文件,config-dev.yml,config-test.yml,config-prod.yml。
新建server模块
引入依赖
1 | <dependency> |
yml配置文件
1 | server: |
在主启动类上添加@EnableConfigServer注解。
Spring Cloud Config 有它的一套访问规则,我们通过这套规则在浏览器上直接访问就可以。
1 | /{application}/{profile}[/{label}] |
{application} 就是应用名称,对应到配置文件上来,就是配置文件的名称部分,例如我上面创建的配置文件。
{profile} 就是配置文件的版本,我们的项目有开发版本、测试环境版本、生产环境版本,对应到配置文件上来就是以 application-{profile}.yml 加以区分,例如application-dev.yml、application-sit.yml、application-prod.yml。
{label} 表示 git 分支,默认是 master 分支,如果项目是以分支做区分也是可以的,那就可以通过不同的 label 来控制访问不同的配置文件了。
测试curl http://localhost:3344/main/config-test.yml
新建client模块
添加依赖
1 | <dependency> |
创建一个bootstrap.yml
注意这里的
bootstrap.yml代表系统级的配置文件,加载优先于application.yml
1 | server: |
测试业务类
1 |
|
测试curl http://localhost:3355/configInfo
动态更新配置
我们修改在GitHub仓库配置文件中的版本信息,server端生效但是client端并没有生效。
在pom中添加actuator依赖
1
2
3
4<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>修改yml,暴露监控端口
1
2
3
4
5
6# 暴露监控端点
management:
endpoints:
web:
exposure:
include: "*"@RefreshScope修饰控制类执行
curl -X POST "http://localhost:3355/actuator/refresh"
Bus
Spring cloud bus通过轻量消息代理连接各个分布的节点。这会用在广播状态的变化(例如配置变化)或者其他的消息指令。Spring bus的一个核心思想是通过分布式的启动器对spring boot应用进行扩展,也可以用来建立一个多个应用之间的通信频道。目前唯一实现的方式是用AMQP消息代理作为通道,同样特性的设置(有些取决于通道的设置)在更多通道的文档中。
大家可以将它理解为管理和传播所有分布式项目中的消息既可,其实本质是利用了MQ的广播机制在分布式的系统中传播消息,目前常用的有Kafka和RabbitMQ。利用bus的机制可以做很多的事情,其中配置中心客户端刷新就是典型的应用场景之一,我们用一张图来描述bus在配置中心使用的机制。
两种方案
- 提交代码触发post给客户端A发送bus/refresh
- 提交代码触发post给Server端发送bus/refresh
第一种方案并不合适,原因如下:
- 打破了微服务的职责单一性。微服务本身是业务模块,它本不应该承担配置刷新的职责。
- 破坏了微服务各节点的对等性。
- 如果客户端ip有变化,这时我们就需要修改WebHook的配置。
流程:
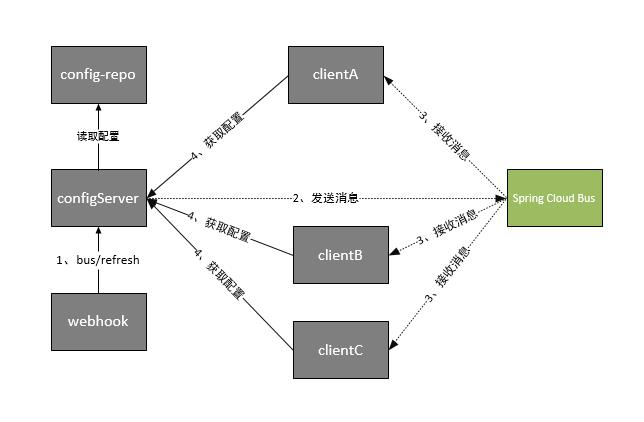
这时Spring Cloud Bus做配置更新步骤如下:
- 提交代码触发post给Server端发送bus/refresh
- Server端接收到请求并发送给Spring Cloud Bus
- Spring Cloud bus接到消息并通知给其它客户端
- 其它客户端接收到通知,请求Server端获取最新配置
- 全部客户端均获取到最新的配置
配置Bus
使用Docker安装RabbitMQ
1
docker run -d --hostname rabbit-host --name rabbitmq -e RABBITMQ_DEFAULT_USER=root -e RABBITMQ_DEFAULT_PASS=root -p 15672:15672 -p 5672:5672 rabbitmq:3-management
服务端模块添加依赖
1
2
3
4<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bus-amqp</artifactId>
</dependency>服务端新增yml配置
1
2
3
4
5
6
7
8
9
10
11
12# mq配置
rabbitmq:
host: 121.196.147.102
port: 5672
username: root
password: root
management:
endpoints:
web:
exposure:
include: "bus-refresh"注意格式缩进
两个服务端同样添加bus的依赖
服务端yml新增
1
2
3
4
5
6
7
8
9
10
11
12
13# mq配置
rabbitmq:
host: 121.196.147.102
port: 5672
username: root
password: root
# 暴露断点
management:
endpoints:
web:
exposure:
include: "*"修改GitHub中对应的版本号。
刷新3344
curl -X POST http://localhost:3344/actuator/bus-refresh实现定点通知
curl -X POST http://localhost:3344/actuator/bus-refresh/config-client-3355:3355,这里的config-client-3355为对应的服务名。
Stream
基本概念
Spring Cloud Stream官方的说法是一个构建消息驱动微服务的框架。我们可以这么理解,这个Spring Cloud Stream封装了mq的玩法,统一了模型,然后屏蔽各个mq产品中间件不同,降低了我们的学习成本,不过目前只支持kafka与rabbitmq。
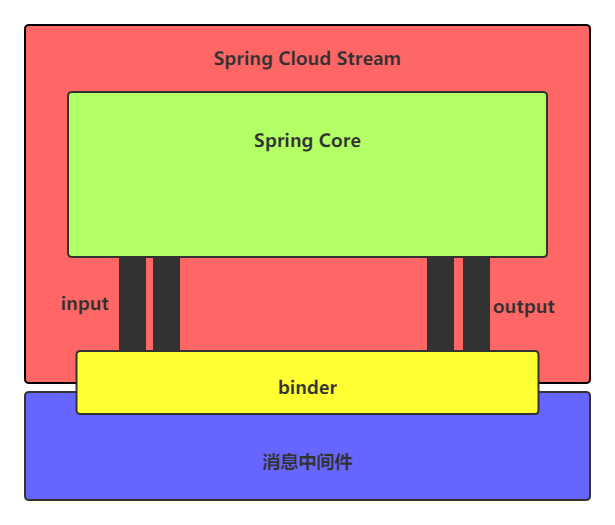
我们从上往下看,我们的应用程序,也就是spring core ,通过这个input 与output 这两种channel 与binder 进行交互,binder(绑定器对象)屏蔽了咱们的消息中间件产品的差异。这个input 与output相对于应用程序来说的,这个input对于应用程序就是读,从外面到程序,output就是写,由应用程序写到外面。
| 组成 | 说明 |
|---|---|
| Middleware | 中间件,目前只支持RabbitMQ和Kafka |
| Binder | Binder是应用与消息中间件之间的封装,目前实行了Kafka和RabbitMQ的Binder,通过Binder可以很方便的连接中间件,可以动态的改变消息类型(对应于Kafka的topic,RabbitMQ的exchange),这些都可以通过配置文件来实现 |
| @Input | 注解标识输入通道,通过该输入通道接收到的消息进入应用程序 |
| @Output | 注解标识输出通道,发布的消息将通过该通道离开应用程序 |
| @StreamListener | 监听队列,用于消费者的队列的消息接收 |
| @EnableBinding | 指信道channel和exchange绑定在一起 |
Stream 的消息通信模式遵循了发布-订阅模式,也就是Topic模式。在RabbitMQ中是Exchange交换机,在Kafka是Topic。
术语
- Binder绑定器,通过binder可以很方便的连接中间件,屏蔽差异。
- Channel通道,是Queue的一种抽象,主要实现存储和转发的媒介。
- Source和Sink,简单的理解为参照对象是Spring Cloud Stream自身,从Stream发布消息就是输出,接收消息就是输入。
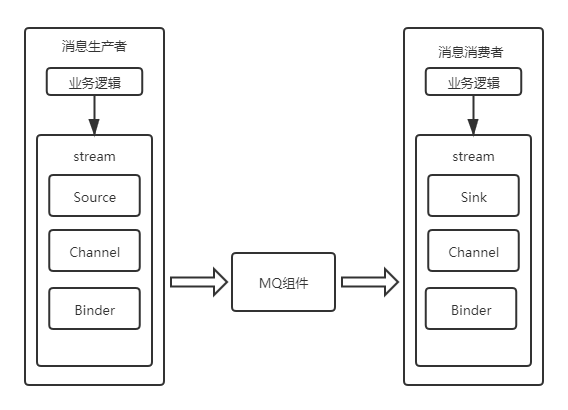
快速搭建
新建消息的生产者
引入依赖
1
2
3
4<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32server:
port: 8801
spring:
application:
name: cloud-stream-provider
cloud:
stream:
binders:
defaultRabbit: # 表示定义的名称,用于binding整合
type: rabbit #消息组件类型
environment: # 设置rabbitmq相关环境配置
spring:
rabbitmq:
host: 121.196.147.102
prot: 5672
username: root
password: root
bindings: # 服务的整合处理
output: # 这个名字是一个通道的名称
destination: studyExchange # 表示要使用的Exchange的名称定义
content-type: application/json # 设置消息类型,本次为json,文本则设置"text/plain"
binder: defaultRabbit #
eureka:
client:
service-url:
defaultZone: http://localhost:7001/eureka
instance:
lease-expiration-duration-in-seconds: 5
lease-renewal-interval-in-seconds: 2 # 设置心跳时间的间隔,默认是30s
instance-id: send-8801.com # 在消息列表时显示的主机名称
prefer-ip-address: true # 访问的路径变为ip地址这里要注意对齐问题,有爆红可以正常启动。
创建消息通道绑定的接口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
164j
(Source.class) // 定义消息的推送管道
public class MessageProvider implements IMessageProvider {
private MessageChannel output; // 消息发送管道
public String send() {
String serial = UUID.randomUUID().toString();
output.send(MessageBuilder.withPayload(serial).build());
log.info("************** serial is {}", serial);
return null;
}
}controller层直接调用就可以了。
新建消息的消费者
同样引入依赖
1
2
3
4<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>application.yml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32server:
port: 8802
spring:
application:
name: cloud-stream-consumer
cloud:
stream:
binders:
defaultRabbit: # 表示定义的名称,用于binding整合
type: rabbit #消息组件类型
environment: # 设置rabbitmq相关环境配置
spring:
rabbitmq:
host: 121.196.147.102
prot: 5672
username: root
password: root
bindings: # 服务的整合处理
input: # 这个名字是一个通道的名称
destination: studyExchange # 表示要使用的Exchange的名称定义
content-type: application/json # 设置消息类型,本次为json,文本则设置"text/plain"
binder: defaultRabbit #
eureka:
client:
service-url:
defaultZone: http://localhost:7001/eureka
instance:
lease-expiration-duration-in-seconds: 5
lease-renewal-interval-in-seconds: 2 # 设置心跳时间的间隔,默认是30s
instance-id: receive-8802.com # 在消息列表时显示的主机名称
prefer-ip-address: true # 访问的路径变为ip地址消费者业务代码
1
2
3
4
5
6
7
8
9
10
11
12
134j
(Sink.class)
public class ReceiveMessageLinstenerController {
("${server.port}")
private String serverPort;
(Sink.INPUT)
public void input(Message<String> message) {
log.info("消费者1号,收到的消息:{}, 服务的端口是{}", message.getPayload(), serverPort);
}
}
分组
在现实的业务场景中,每一个微服务应用为了实现高可用和负载均衡,都会集群部署,按照上面我们启动了两个应用的实例,消息被重复消费了两次。为解决这个问题,Spring Cloud Stream 中提供了消费组,通过配置 spring.cloud.stream.bindings.input.group 属性为应用指定一个组名,下面修改下配置文件,修改如下:
1 | bindings: # 服务的整合处理 |

在MQ的可视化中可以发现当前group下存在两个消费者。
测试即可。
Sleuth
在微服务架构中,众多的微服务之间互相调用,如何清晰地记录服务的调用链路是一个需要解决的问题。同时,由于各种原因,跨进程的服务调用失败时,运维人员希望能够通过查看日志和查看服务之间的调用关系来定位问题,而Spring cloud sleuth组件正是为了解决微服务跟踪的组件。单纯的理解链路追踪,就是指一次任务的开始到结束,期间调用的所有系统及耗时(时间跨度)都可以完整的记录下来,
Zipkin服务端部署
服务端是一个单独的jar包,官网貌似已经下载不了了,去Maven仓库下载即可。
1 | java -jar zipkin-server-2.12.9-exec.jar |
客户端部署
引入依赖
1
2
3
4<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>配置文件
1
2
3
4
5
6spring:
zipkin:
base-url: http://121.196.147.102:9411
sleuth:
sampler:
percentage: 1.0 # 收集数据百分比,默认 0.1(10%)访问
http://121.196.147.102:9411/即可